超参数与西山居联合发布3D生存类游戏AI“猎户座α”
副标题[/!--empirenews.page--]

2016年AlphaGo诞生之后,短短三年间,星际、Dota2、德州扑克、麻将相继被AI攻克。随着OpenAI Five和AlphaStar血洗天梯竞技场,游戏领域似乎已经被AI完全拿下,不过目前依旧有两个问题尚未解决。 其一是环境的复杂度问题。电子游戏作为‘第九艺术’的最大魅力在于虚拟世界对现实世界的仿真模拟。但是,目前AI已攻克的游戏,大部分是运行在2D空间内。即使是3D空间的DeepMind雷神之锤3 AI,也是基于上世代的游戏内核,地图简单、智能体数量少。这里的游戏AI能力能否迁移到现实世界是存疑的。 其二是AI的拟人度问题。现有的游戏AI主要以竞技为目的,追求更高的胜率和段位。但从开发商和玩家的角度,AI并不只是越强越好,还要求越像玩家越好。以射击游戏为例,简单几行代码写出的AI就可以轻松碾压人类,但谁会自讨没趣找一个自瞄锁头的AI对战呢? 基于上述两点,我们认为,具有复杂3D环境、要求多人在线的3D生存类游戏将成为AI的下一大挑战。 在西山居研发中的战术竞技游戏《荣耀之海》中,我们开发了名为“猎户座α”的AI,并具备了复杂3D环境感知、物资搜索/使用、作战、团队配合等全方位的能力。 问题有多复杂 《荣耀之海》是西山居自主研发的新一代多人在线战术竞技游戏。游戏主打时下最火热的“吃鸡”玩法,百名玩家通过海上与陆上的大逃杀决出胜者。 作为一款3D游戏,复杂度相比一般2D游戏已经上了一个台阶,而吃鸡类游戏的超大地图、百人同局等要素又进一步增加了技术难度。 而具体来说,AI需要处理的挑战包括: 1)实时性与长期性 玩家不仅要做出实时的操作决策,还要做出长期的规划决策,平衡兼顾两者。为了最终获胜,整局游戏通常需要进行30分钟以上,对应的决策步数在7000步以上。 2)非完美信息 在3D游戏中,玩家只能看到一定视角范围内的信息,并且无法看到被障碍物遮挡住的信息。因此,玩家需要有效探索不可见的信息,并具备记忆能力。 3)复杂的状态空间 3D环境比2D环境包括更多的信息,例如带深度的复杂空间结构、庞大的地图(10公里*10公里)、众多的玩家(100人)、丰富的元素(大量建筑、障碍、物资等),对环境感知和探索提出了巨大挑战。 4)复杂的动作空间 玩家需要同时操作移动方向、视角方向、攻击、姿态(站、蹲、趴、跳)、交互(拾取、打药、换弹)等一系列操作,产生复杂的组合动作空间。我们估算离散化后的可行动作数量在10^7这个数量级。 5)战略与战术 玩家需要对瞬息万变的环境和局势做出快速准确的判断,采取丰富的战略和战术,例如火力掩护、拉枪线、抢点、卡毒圈、封烟救援等等。 6)多人博弈 玩家不仅需要与队友进行密切的合作和通信,还需要与其他队伍在资源搜集、武装交火时进行对抗。与两人博弈相比,多人博弈的情况会更加复杂多变。 上述这些难点也是导致行为树AI不可能做出复杂、拟人操作的主要原因。 我们在本阶段的研究聚焦于一个迷你对局(mini-game)――在230米*230米岛屿上、时限6分钟内、组队2V2,最终存活的一方获胜。除这些限制外,其他游戏元素与完整游戏完全相同。 超参数的实现路径 “猎户座α”采用了深度强化学习方法,从零开始,通过与环境的交互和试错,学会观察世界、执行动作、合作与竞争策略。AI没有使用任何人类玩家的对战数据,完全基于自我对战(self-play)的方式进行学习。 AI观测的状态信息包括玩家/物资的实体信息、深度图、雷达图、小地图,以及宏观标量信息。与人类一样,AI观测到的状态是非完美的――即只能看到一定视角范围内的信息,看不到视野外或是被障碍物遮挡住的信息。 与直接用RGB图像作为特征相比,超参数的方式省去了图像目标检测和识别的过程,专注在AI的决策过程。此外,雷达图和小地图相当于自动驾驶中的高精度地图,深度图相当于深度摄像机捕捉到的信息。 AI的动作输出分为移动方向、水平/俯仰朝向、身体姿态、物资拾取/使用、武器切换、攻击等任务,多个任务可以同时执行,形成巨大的复合动作空间。人类玩家在操作时,会存在反应时间的限制,APM(每分钟操作次数)也会有上限。 为了与人类玩家操作一致,我们对AI也进行了相应限制。考虑到网络传输延时、特征提取和模型预测的耗时,AI从“观测到1帧状态”到“产生1次动作”需要120ms的延时。在此基础上,超参数额外增加了100ms延时。同时,AI每秒最多执行4次动作、每次最多包含3个动作。 每个AI是一个深度神经网络模型,输入状态信息,输出预测的动作指令。我们通过Transformer模型处理玩家、物资等实体信息,通过ResNet处理深度图、雷达图、小地图等图像信息,通过MLP模型处理宏观标量信息,然后通过LSTM模型实现记忆能力。 为实现多智能体合作,我们采用了分布式的策略网络和中心式的价值网络,并引入了策略网络之间的通信机制。 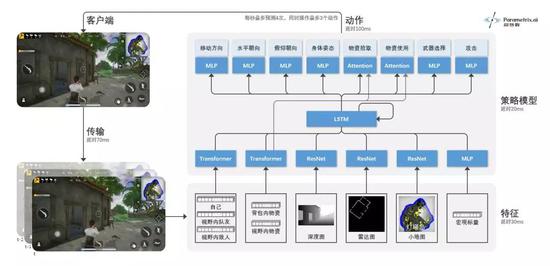 AI模型结构示意图 AI模型结构示意图
“猎户座α”的训练在超参数自研的通用分布式强化学习引擎Delta上进行。该引擎通过大量弹性CPU资源产生训练数据,通过GPU资源更新神经网络模型参数,并且可以通过监控组件监控AI的训练过程。在该项目中,“猎户座α”训练一天相当于人类玩家打了10万年。该引擎可以部署在任何公有云上,目前已经支持了多款游戏的AI训练。 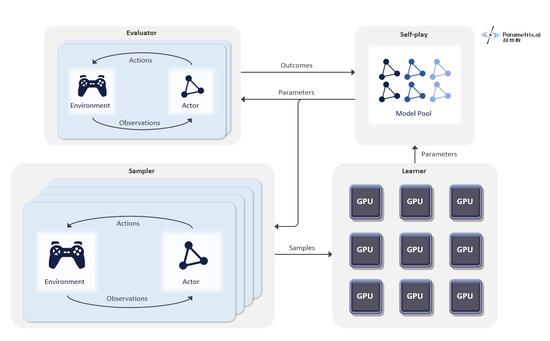 分布式强化学习引擎Delta架构示意图 分布式强化学习引擎Delta架构示意图
目前达到的效果 我们看到“猎户座α”从零开始逐渐学会了在3D环境中生存所需的全方位能力。 AI学会了通过搜集物资和跑毒来照顾好自己: 
(编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |